Note: The following text from Brian Schwind, Remote Sensing Specialist is part of metadata provided with the U.S. Forest Service vegetation coverage used in the KRIS Noyo Map project. The project was created by the Pacific Southwest Region Remote Sensing Lab, 1920 20th Street, Sacramento, CA 95814. Brian may be reached at: bschwind/r5_rsl@fs.fed.us.
VEGETATION CLASSIFICATION AND MAPPING
In forestry, the need often arises to map and inventory vegetation, as an assessment of its condition. Conventional methods use manual interpretation of stereoscopic aerial photography to delineate areas of homogeneous vegetation (usually termed stands) using analysis of image tone, texture, and topography. With the availability of computers and satellite imagery, automated procedures have been developed to capture the same attributes for delineating stands.
CONVENTIONAL VERSUS AUTOMATED METHOD
The conventional methodology used to produce vegetation maps begins with the delineation and mapping of forest stands. Natural resource professionals skilled in air photointerpretation techniques use conventional resource photography, typically normal color, 9" x 9" positive prints at a scale of 1:15,840 or 1:24,000, to delineate forest stands by drawing boundaries around homogeneous areas of uniform vegetation. Typically, a minimum size of five acres will be required for delineation. Concurrent with the delineation process, the stand boundaries are transferred manually from the air photos to 7-1/2 minute topographic quadrangles, and labels are affixed to each stand indicating the species composition, height, crown density, and other features of interest for forest management purposes. The stand maps which are thus produced are a basic information resource, widely used at the National Forest and Ranger District levels. Because this process is based on manual photointerpretation, it can be time consuming and costly, as well as inconsistent from analyst to analyst.
The boundaries on the stand maps are then scanned photomechanically and input into an automated, computerized data base system which is manipulated through the Geographic Information System, GIS software. Once scanned and edited, the polygons are displayed by map section with a GIS system and stand labels are assigned to the polygons. Unfortunately, the labeling process is, at the present time, relatively costly and labor intensive.
Automated methods of mapping forest vegetation, both spatially and thematically, have been developed over the last 15 years using image processing and GIS technology. They have designed to overcome the problems of conventional methods, through the use of computer processing techniques to extract and process tonal, textural, and terrain information. Major sources of informational data input consist of registered Landsat Thematic Mapper imagery, high resolution imagery (SPOT, IRS), digital terrain data, and ground based information used in map classification, stand delineations, canopy, size class, and ecological modeling.
Comparison of samples from forest strata identified by the automated method, with strata identified by conventional procedures, showed that both have about the same potential to reduce the variance of timber volume estimates over simple random sampling.
The automated method bypasses manual photointerpretation for both stand delineation and vegetation characterization by using segmentation and classification of satellite imagery and registered digital terrain data. Labeling of the automatically defined classes is still required; however, this labeling can be done much more rapidly and efficiently than in the conventional procedure. Furthermore, by utilizing image processing software systems, the classified images, which are the analog of stand maps, can be directly interfaced through software to a multi-attribute geospatial database.
AUTOMATED CLASSIFICATION OF FOREST VEGETATION
In mapping existing vegetation for large area inventories, habitat analysis, fire fuels modeling, and other vegetation based information needs, four key attributes characterize each forest stand or region: life form, species types (CALVEG), and for forest types; average visible tree crown size, and canopy closure. Each of these attributes is characterized independantly and in a hierarchical fashion. A hierarchical approach that first classes the most general landscape features (life form) results in a foundation onto which more detailed floristic and structural information can be added. Mapping each of these attributes independantly minimizes the confusion between attributes that have only slight image tone and texture differences.
Additionally, mapping vegetation attributes seperately allows for the most appropriate classification technique to be applied. For example, unsupervised classification has been shown to be effective for mapping life forms and tree crown size but relatively poor as a singular technique for vegetation type.
The basis of mapping existing vegetation with remote sensing techniques is to use the same three characteristics of tone, texture, and terrain that the photointerpreter uses in delineating forest stands or region boundaries, as well as life form classification. Landsat imagery reflectance vectors provide tonal information for brightness and greenness, and Digital Elevation Model (DEM) 1/24,000 or Defense Mapping Agency (DMA) 1/250,000 digital terrain data provide the required terrain information. Texture data are derived from Landsat imagery.
The computer processing is carried out using ERDAS Imagine, Image Processing Workbench (IPW) or similar image processing systems, in combination with ARC-INFO or other geographic information system that support raster based layers. Integration of existing GIS layers of water bodies from Cartographic Feature Files (CFFs) and mapped areas of plantations and non-stocked forest land on wildfire areas are used to make the final vegetation maps more accurate.
In a departure from the traditional method of stand delineation, an automated, systematic method of generating spatial, unattributted stands or regions is used. Stand delineations are independant of map attribute classification so as to avoid reducing spatial accuracy by incorporating error inherent in thematic classifications. Through the application of image segmentation algorithms, consistent delineations of landscape features and growth forms are created based on user defined spectral and spatial parameters (See Figure #1). This process allows for stand delineations more quickly and efficiently than traditional photo interpretation techniques. Image derived stands are subsequently combined with vegetation attribute maps through GIS software to produce a stand-based, multi-attribute vegetation database (See Figures #2,#3).
Life form mapping is performed using unsupervised classification techniques. Tree size class is also mapped using this technique, or in combination with supervised classification. In either case, a large number of ground observations of stands with different average tree sizes is necessary to produce reliable maps for this attribute.
Typically, in an automated, hierarchical vegetation mapping process, vegetation species is the next level of map information produced following life form classification. Because forest composition varies systematically with terrain, species type can be modeled using terrain data and acillary GIS data. To quantify the relationship between elevation, slope, aspect, and CALVEG type, field data is required. The simplest method of quantification involves systematically observing each CALVEG type at all aspects, slopes and elevations, and plotting this on a graph. If ecological relationships vary across a Forest, geographical areas or Natural Regions, this needs to be identified and unique mapping rules developed for each Region.
An additional technique has more recently been developed for modeling canopy closure. This requires the collection of in-place stand information on tree vegetation as training and calibration sites for the geometry of tree canopies. The ground based information, evaluated with terrain data, position, temporal characteristics of satellite image capture, and various image band combinations are used to predict an estimate of canopy closure for each forest stand.
LIFE FORM CLASSIFICATION
Prior to modeling ecological relationships for vegetation type, the Landsat image is classified into several life forms: conifer, hardwoods, mixed, shrub, wet herbaceous, dry herbaceous, barren, water, snow, agricultural and urban. Other more specific vegetation types that have unique spectral properties may be mapped at this time as well.
Cloud areas are also distinguished in this step and are subsequently classified into one of the above life forms, utilizing various techniques. Plantations are added as a separate layer, to distinguish productive forest land from shrub, meadow, grass or barren classes. Water bodies are also added from CFFs, where available, in order to maintain spatial consistency in lakes.
Image classification produces a "pixel-based" land cover map utilizing an unsupervised classification technique. This technique produces spectral cluster classes known as a "per pixel classification". A large number of classes are produced, which are then processed by an analyst into simpler, smaller sets and labeled with the appropriate life form.
Image classification occurs with individual pixels, not stands. Therefore, an additional step utilizes an image segmentation procedure which delineates stand boundaries, based on spectral similarities. When combined with the per pixel classification, a "stand based" land cover map is produced. This map is then passed through a decision rule process, which utilizes analyst specified decision rules to label the stands or polygons, based on the per pixel classification. Although life forms classification is based on spectral differences, decision rules are utilized to determine conifer, hardwood and shrub polygons from each other. The decision rules are determined by the classification system (See Table #) and further influenced by the analyst who compensates for class variation within a specific classification product. The decision rules are to label a polygon as conifer if 10% of the tree canopy cover is conifer. If there is less than 10% conifer canopy cover, but at least 10% hardwood cover, the polygon is labeled as hardwood. If less than 10% tree cover exists, and there is at least 10% cover of shrubs, the polygon is labeled as shrubs. Otherwise it will be labeled as one of the other categories based on plurality. Editing is then carried out on these stands or polygons to resolve any ambiguous results for life form. This stand life form map is then used as input to the ecological terrain model.
MODELING ECOLOGICAL RELATIONSHIPS
Observations in western coniferous forest areas have shown that forest composition varies systematically with topography in many places. The distribution patterns of coniferous species have long been associated with particular elevation ranges; species are often referred to as "low elevation" or "high elevation" species. Red fir, for example, is usually considered a high elevation species. Compass aspect (direction which a slope faces) has also been recognized as influencing tree growth and species distribution. North to northeast exposures are typically more favorable for tree growth than drier southwestern exposures (in the northern hemisphere). As a result, species that exhibit elevational zonation tend to occur at lower elevations on northeast-facing slopes. These terrain relationships represent climatic influences, in particular moisture and temperature, that control species distributions. Satellite remote sensing is used for mapping the life forms of conifer, hardwoods, shrubs, meadows, barren, grass and water. However, remote sensing is not particularly strong in differentiating species or groups of species that are similar, since the variation in spectral signatures can be large. Therefore, the terrain variables of elevation, slope and aspect have proven useful in modeling species associations (Macomber et al. 1991).
Natural Regions. Because a large National Forest may exhibit extensive climatic, geologic, and ecological diversity, plant species-habitat relationships and spectral signatures (light reflectance) which characterize particular vegetation types, are not likely to be the same in all portions. Therefore, the project area is divided into Natural Regions in which ecological relationships remain fairly constant and signature extension should be valid within a particular Natural Region. This not only facilitates the accuracy of ecological type modeling within Natural Regions, but also serves as "processing areas" to simplify image processing work areas.
Natural Regions are defined as areas within which the elevation-aspect ranges of the various major vegetation types remain constant. Traditionally, Natural Regions have been designated primarily on the basis of ground reconnaissance, interviews with resource professionals familiar with a particular area, and relevant background material (i.e. geology maps, isohyetal maps, published documentation). With the implementation of the National Hierarchical Framework of Ecological Units (ECOMAP), Section and Sub-Section divisions of the ECOMAP are now used to determine appropriate natural regions (See Figure #).
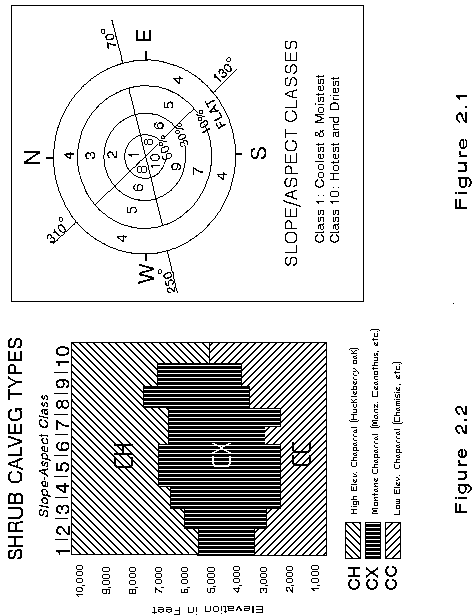
Digital Terrain Processing. USGS digital elevation models (DEM) are used to derive classes for elevation and slope/aspect as input to the modeling process with Image Processing software. DEM images are first mosaicked to cover the area of the Landsat TM image, then registered to the Landsat scene and resampled to match the TM image.
Elevation and slope/aspect images are then converted to ARC/INFO grids. Slope is divided into 4 classes and aspect into 3 classes (See Figure 2.1). The resultant combination classes represent incremental levels of solar insolation with class 1 being the coolest and moistest and class 13 the hottest and driest. Slope and aspect also influence parameters such as soil development, which exerts environmental influences on plant species composition. Where significant correlations of species composition to soil type are observed, digital soil layers may also be utilized as a model input.
Building an Ecological Terrain Model. Field training site data is collected to form the basis for the ecological terrain modeling. Observations are made throughout the project area, within each natural region, to sample the range of elevation/slope/aspect combinations. Quad maps and aerial photography are used to collect the data. Observations are recorded for the occurrence of each major vegetation type at different locations to determine the extent of a type within a natural region. Slope angle, elevation and aspect are recorded for conifer, hardwood and shrub types that occur within a natural region.
Particular attention is paid to the elevation/slope/aspect combinations where vegetation changes. For example, a Mixed Conifer - Fir forest type can occur within an elevational band of up to 7000 feet in a particular natural region. On north aspects above 7000 feet, Red Fir becomes the major type. However, Red Fir may not occur on south aspects until an elevation of 8000 feet and may not occur at all on south aspects with greater than 60% slope. In addition to recording the elevation/slope/aspect combinations of different vegetation types, field notes are also collected with more detail on species composition throughout a project area (See Section 231 for Field Notes form). This will facilitate descriptions for vegetation types within a project area, as well as provide additional data needed for crosswalking between classification systems.
After field data collection, the data is transferred to a matrix graph which assigns a type to a combination of elevation and slope/aspect class (Figure 2.2). In addition to field data, any ancillary data such as old vegetation maps, ecological classification data, silvicultural stand exam data, etc., that exists will be utilized to make decisions about what types occur across a natural region and where vegetation types change within a matrix graph. Each natural region will have three matrix graphs completed, one each for conifers, hardwoods and shrubs. Obviously, there is some generalization about the compositions of each type and the actual "boxes" where change takes place; however, this method can improve the results for mapping vegetation types across large land areas, than with using spectral signatures alone.
CALVEG is the classification system being used for the mapping of existing vegetation. A key to the CALVEG types being mapped is provided in Appendix B. After the types are plotted on matrix graphs and separated in slope-aspect-elevation space, rules for the prediction of CALVEG types are developed. This utilizes a function of GRASS GIS software called r.infer. The input for the rules are the elevation maps and the slope/aspect maps that were already created in IPW and GRASS. These "rules" produce a separate "map" for conifers, hardwoods and shrubs within each natural region. This map represents the potential for finding a particular existing vegetation type at the specified elevation and slope/aspect class, based on field training site data and ancillary ecological information.
The final step is to combine these layers with the stand based cover map which represents life form for the area. The GRASS function r.infer is again used to produce this final vegetation type or CALVEG layer for the final map products. In this step, a control file is written which takes life form classification and then applies the rules that were derived for the prediction of CALVEG types. In this way, all conifers, hardwoods and shrubs, within a natural region, are assigned a specific type or series level label of the CALVEG classification system based on these rules. Meadows and dry grass were previously broken out during life form image classification and polygon formation, and do not undergo more specific identification. The basic process is to intersect separate layers in a geographic information system; the life form layer together with each model layer representing the potential types for conifers, hardwoods and shrubs.
Not all vegetation types can be modeled with terrain data. Examples include: vegetation growing on serpentines, and those with specific moisture or soil requirements, such as Lodgepole Pine. In these cases, ancillary information is sought out which can delineate where these areas can occur. Resource professionals from the National Forests very often have mapped these areas or know where they occur. In such cases, these are brought in as another GIS layer which then "supercedes" the results of the ecological terrain model. The quality of vegetation type maps produced from remote sensing can be greatly improved with specific information derived from ancillary data, both in the use of building the terrain model, and to delineate types which are not as directly influenced by terrain variables. In some cases, ecological modeling may consider differences in soils or geology as variables to be input into type modeling, particularly in areas where terrain does not strongly influence vegetation compositions.
CALVEG Classification System. The CALVEG Classification System is a statewide system developed by the U.S. Forest Service to serve as a standard for existing vegetation maps. Whereas regional forest types are groupings used for forest canopy modeling, inventory and general planning, the CALVEG classification can be more suitable for multiple-use resource information needs of the National Forests. The key in Appendix B can serve as criteria for separating CALVEG types from each other. More detailed descriptions are available in the U.S. Forest Service document CALVEG: A Classification of California Vegetation. Some descriptions have been refined further than what is in this document, to provide more specificity of type descriptions for particular National Forest mapping projects.
FIELD NOTES RECORD
MAJOR VEGETATION TYPE - FIELD NOTES
Date: ___________________ Observer: _______________________________________
Observation Quad No.: ________________
Point No. : ______________ Photo No.: ________________
Slope: _______________ Aspect: ________________ Elevation: _______________
Overstory Total Tree Overstory Total Conifer
Canopy Cover % : __________________ Canopy Cover % : _____________________
Overstory Total
Hardwood Total Shrub Total Herb
Canopy Cover % : ___________________ Cover % : ______________ Cover %: _______________
(Forbs/Graminoids/Ferns)
-----------------------------------------------------------------------------------------------------------------------------
Species %Cover Species %Cover
Overstory______________ _______________ Shrubs ________________ _______________
Conifers
______________ _______________ ________________ _______________
______________ _______________ ________________ _______________
______________ _______________ ________________ _______________
______________ _______________ ________________ _______________
______________ _______________ ________________ _______________
Hardwoods_____________ _______________ Forbs ________________ _______________
Ferns
______________ _______________ Grasses _______________ _______________
______________ _______________ ________________ _______________
______________ _______________ ________________ _______________
______________ _______________ ________________ _______________
______________ _______________ ________________ _______________
CalVeg Type _______________________ WHR Type __________________________
FOREST CANOPY MODELING
The Canopy Model. Canopy modeling is accomplished using geometric modeling procedures. The canopy model is used to obtain estimates of "treeness" or values of "M", which are in turn inverted to give estimates of canopy closure as percent cover values for each forest stand or region. The canopy model is a four component model consisting of; sunlit tree crowns, sunlit background, shaded tree crowns and shaded background (See Figure 2.3). This is essentially a mixture model, that mimics the light sources (or lack of light) contributing to reflectance values for each 30 meter pixel area of a Landsat image brightness-greenness band combination, and how it varies between pixels within a stand.
Compensating for Illumination. For most National Forest land, the area being classified contains rugged terrain. Terrain effects how the sunlight is reflected or absorbed by an object or surface and the intensity of the sunlight received, which causes increased variance in the spectral values of the Landsat image. The variation is produced by differential illumination of slopes (shadows) caused by high topographic variation combined with low sun angle at the time, about 10:00 AM for our location, of the Landsat overpass. To minimize this effect, mid to late summer image dates are obtained, when the sun angle is the highest, and the shaded slopes receive the most sunlight. Even so, the more densely stocked forest areas with normal illumination have the same spectral reflectance as more sparsely stocked areas in poorly illuminated or shaded areas. This problem rules out the separation of forest canopy attributes based solely on spectral reflectances. Thus, it is necessary to develop a means of separating the image into categories based on illumination conditions at the time of the Landsat overpass.
The registered terrain data are used to model illumination conditions for each pixel within a stand or region. The angle between a normal-to-the-land surface and the sun at the time of the Landsat overpass is calculated. For a diffuse (Lambertian) reflector, the apparent brightness of a surface under constant illumination at an angle z will be proportional to cos(z). Thus, a cos(z) image displays the brightest values for pixels directly facing the sun and the darkest values for pixels in shade. From the cos(z) image, a mask is created to divide the image into two categories based on illumination: well-illuminated, and poorly-illuminated (shaded). The cutoff between these two categories is a zenith angle of 60 degrees; areas with angles greater than 60 degrees are considered poorly-illuminated.
The mask of shaded and well-illuminated pixels is created and serves to divide the area being mapped into its shaded and unshaded components. Since only a small percent of the image will be shaded, however, many classes remain undivided. The result of this action is to reduce within-class variation effectively and remove a potentially adverse effect on the predictive process.
Canopy Model Inputs. The canopy model requires several kinds of information; Landsat imagery, time and location of the satellite when the image was taken, topography of the stands, average crown length to crown radius by regional forest type, and component signatures from known locations with known values for the model components.
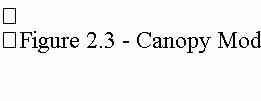
The Landsat image is re-combined into two transformations, brightness and greenness. These are used in both the signature estimation procedure, as well as values for each pixel in a forest stand.
The time and location of the satellite are used to calculate the local solar zenith, and are used in combination with the slope and aspect information to determine the surface geometry of each stand.
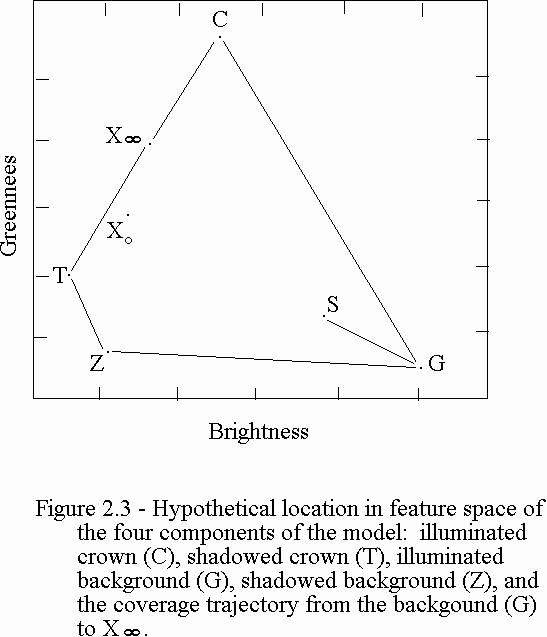
Data collected from a number of individual stands are used to calibrate the component signatures of the canopy model; shaded and sunlit crowns and background for each regional forest type, as well as to develop the tree geometry parameters of crown length to crown radius, b to r ratio (See Figure 2.4).
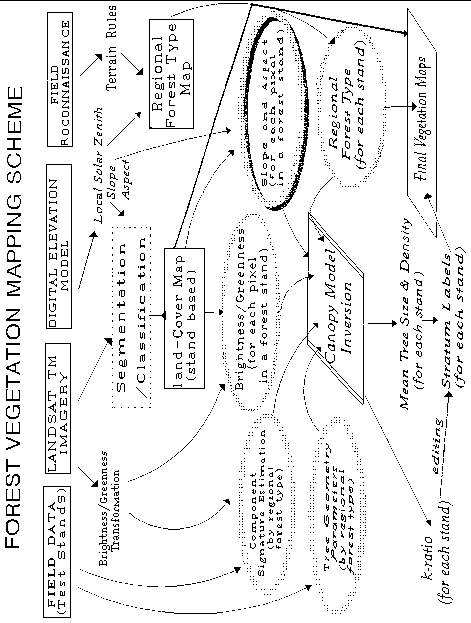
After the crown model is calibrated using detailed information for known stands, the model is run across the entire map area for all pixels within stands. This is done for each regional forest type. For all stands labeled with the same regional type, an estimate of "M" or treeness is determined for each pixel, and then inverted to obtain estimates of canopy cover for each stand. (See Figure 2.5, Forest Vegetation Mapping Scheme.)
Figure 2.5 - Forest Vegetation Mapping Scheme
TREE SIZE CLASS ESTIMATIONS
Estimating average tree size class is the hardest stand attribute to obtain from image processing techniques, or directly from aerial photos. This is due to several factors, none of which are totally independent. What is seen from aerial photos is the visible crowns from a "birds eye view". Trees and portion of tree crowns are hidden from view by the shadowing and overlapping of trees in the upper canopy, and thus, only part of what is actually in a forest stand can be measured directly on aerial photos. What can be directly measured is the visible crown diameter of the top story trees. Because crown diameter and tree diameter at breast height (DBH) are highly correlated, estimates of tree size can be made by measuring their crowns. However, crown width to DBH relationships do vary by species, especially for hardwoods compared to conifers. The other key factor causing estimation errors in average tree size is where stands are made up of trees of different sizes, from large to small. This is the case for many stands found in California due to fire, pests and harvesting history.
When estimating tree size using Landsat imagery, a large number of training stands are required to overcome this problem. Most of the reflected light received from the ground to the satellite is a function of tree canopy cover, not tree size. Although tree size does affect the texture of the image, it also affects the measure of variance of neighboring pixel values where the larger the variance value, the larger the trees; this same effect can be from clumped small trees with bright background areas between the clumps. This problem causes the worst kind of confusion, large trees confused with small trees.
The most reliable procedure to map average tree size is to use unsupervised classification. For all pixels classified as trees, these areas are now re-classified for tree size using the information from known stands that are homogenous in tree size. The focus of the classification is to concentrate on separating the small pole size trees from the large timber size trees, and default the remaining into the medium size class. Although this procedure is not as exacting as doing detailed measurements on aerial photos or in-place stand exams, it does produce a useable map when combined with the plantation layer for the smaller seedling, sapling and pole stand sizes.
COLLECTING TRAINING SITE INFORMATION
Field Data Collection - Canopy/Size
It is important to have accurate field data in each of the major forest types in order to model canopy cover and conduct unsupervised classification for size classes. Our approach is to model canopy cover based on the geometry of forest canopies and the position of the sun. This approach allows for variation in the bi-directional reflectance of forest canopies and the effects of sun angles, surface topography, background vegetation and shadowing. Field data therefore, must reflect the range of conditions that are encountered within a project area.
Based on field reconnaissance, published material, and discussion with knowledgeable local experts, major forest types (conifers and hardwoods) for the project area are identified. Major forest types correspond to CALVEG Series Level types; for example: Red Fir, Eastside Pine, Blue Oak, etc. Training stands are chosen as a representative sample of each major forest type, on illuminated, shaded and flat slopes. Illuminated slopes are those at a south-southeast aspect and greater than 30% slope; shaded are on north-northwest aspects and greater than 30% slope; and flat are those with less than 20% slope. This describes the mid-range of possible illumination conditions (flat) and the two extremes (shaded and illuminated) for calibrating the canopy model. Training stands are further stratified by canopy cover class: 10-30%, 31-69%, and greater than 70% canopy closure. Training stands are chosen with aerial photography interpretation to determine if they meet the sets of condition described above. In addition, they should be at least 10 acres in size and homogenous in canopy cover. Further verification of training stands that meet the above set of conditions occurs in the field before data collection.
For each canopy model training site, a 16-point grid is installed (Quick Plot Stand Exam, See Section 374 for plot configuration), with points located at equal distances from each other. The distance between points varies with the size of the stand, to sample all portions of the area. At each point, information on elevation, slope and aspect is recorded. A variable-radius plot is used, and for all trees that fall in the plot, species, crown position, crown ratio and diameter at breast height (DBH) are recorded. At each point, one tree (first tree from north) will also have height and crown diameters measured. Two site trees are located within each training site, to core for age and determine the site index for the stand. Information is also collected on "background" found beneath the canopy, including percent cover of seedlings, saplings, shrubs, forbs and grasses, and any ground material (rock, duff, etc.) that may be present.
Size canopy training sites must also include a range of all major forest types in the project area on illuminated, shaded and flat conditions across 4 size class groups. These classes are for poles (6-12" DBH), small trees (12-24" DBH), medium trees (25-36" DBH) and large trees (greater than 40"). Again, each training site must be at least 10 acres in size, and fairly homogenous with regards to size class. Stands should also be single-storied, even-aged stands, with moderate crown density. No field data are collected, since they are used for an unsupervised classification, not a modeling technique. The stand is delineated on aerial photographs and topographic quadrangles, and information on type (species composition), tree size class and illumination angle are recorded.
Training site data are processed and summarized using the USFS Region 5 Forest Inventory and Analysis System (USFS-Region 5, 1994) software for input into the canopy model and size classification.
INTEGRATING REMOTE SENSING PRODUCTS IN GIS
Unlike the conventional method of vegetation mapping where the stand maps must be photo-to-map transferred, scanned or digitized and labeled, the automated classification data file is converted from pixel format (raster), to polygon format (vector). Most GIS software can accommodate this as a standard routine. The resultant vegetation map is now a layer in the GIS data base which may be overlaid with administrative, compartment, and/or watershed boundaries. If plantations, non-stocked forest areas from fires, and/or water bodies have not been incorporated during the mapping phase, they can now be used to over-ride these areas, by using the GIS software to update the vegetation maps. Once the map update and overlay process is complete, net National Forest acre values can be calculated for each unique vegetation label or attribute of interest, broad life form or CALVEG type. Maps can be easily produced for use in forest inventory, land management planning, watershed analysis or landscape analysis projects.
ACCURACY ASSESSMENT
All vegetation type maps contain errors. It is impossible to create absolutely accurate delineations between vegetation types, largely because vegetation does not grow in homogenous patches or stands. By nature, vegetation boundaries are likely to be diffuse, or fuzzy, rather than sharp and contrasting. Errors can be of several types. Errors of omission occur when "conifers are mapped as something other than conifers". Conversely, an error of commission occurs when "shrubs are mapped as conifers". Registration errors can affect large areas of a map, causing the boundary lines to be shifted in one direction.
Accuracy assessment of maps improves their utility by providing the user of the maps with information about the nature, magnitude, frequency and source of errors. If the user knows that some of the conifers are mapped as something other than conifer, it will help explain why the total acreage of conifer falls short of expected values. On the other hand, if the acreage of conifer seems excessive, it could well be because many of the shrubs were mapped as conifer. An accuracy assessment can be conducted in a variety of ways, but the two primary methods are the Error Matrix, and the Fuzzy Set.
An error matrix involves comparing mapped labels with on-the-ground conditions at the site. The observer has only to determine if the mapped label is right or wrong. If the mapped unit is "conifer" and the observer finds shrubs, it counts as an error. A matrix table is constructed using mapped labels on one axis, and observed conditions on the other axis. The higher the proportion of "matches" there are, the more accurate the map is. The error matrix is sometimes referred to as a "Confusion Table" because it can highlight the types that are often confused. If 25% of the sites labeled conifer actually contain shrubs, then it can be inferred that there is a high level of confusion between conifer and shrubs.
Fuzzy Set theory goes a step beyond looking at right vs. wrong and confusion. It requires that the observer, without knowledge of the map label, make an unbiased evaluation of the site and rate all possible labels on a relative scale from "absolutely right" to "absolutely wrong". For example, if the observer was evaluating a pure red fir stand, he/she would rate a label of "hardwoods" as absolutely wrong, but might rate "mixed conifer-fir" as wrong, but close. Or a shrub/hardwood site might get an OK rating for either the "shrub" or "hardwood" label, but would receive "absolutely wrong" for a conifer label.
The benefit of using Fuzzy Set accuracy assessment is that it provides more information about the nature of errors, their magnitude and where they are likely to occur. Below is an example from the accuracy assessment recently completed on a forest mapping project.
"Polygons labeled conifer can reliably be expected to be conifers except on steep, northwest-facing slopes where confusion with hardwoods may occur."
Regardless of how carefully a vegetation map is prepared, there will always be errors. An accuracy assessment is essential to provide the map user with the necessary information to interpret the map wisely. Forest inventory information can be used in the preparation of accuracy assessments, as long as all unique vegetation types and conditions are sampled in a non-biased fashion.